En primer lugar, existen varias fuentes abiertas de consulta, que a veces son olvidadas al momento de buscar una respuesta:
| La Ayuda en Línea de Plex | La ayuda de Plex es casi autosuficiente; es un universo completo, donde podríamos destacar la Base de Conocimientos, y la Referencia. Sin embargo, siempre haga una pasada por el Getting Started/New Users, donde encontrará, no solo los tutorials, sino los modelos de ejemplo, y las preguntas frecuentes, que puede encontrar ampliadas en el sitio de Nicola Zordan (no en el indicado en la ayuda) |
| El sitio de soporte de Computer Associates, usando el STARTCC, si tiene el privilegio de poder accederlo. (Por alguna razón comercial, algunos países parecen no poder acceder en forma directa a este recurso) | Existe siempre la posibilidad, si usted mantiene un contrato de soporte, de recurrir al soporte directo de CA, y rever la base de conocimientos. Si usted no tiene esa entrada, todavía le quedan dos posibilidades: las FAQs, que aportan bastante, y los foros de usuarios, que muestran poca participación y seguimiento |
| El Foro EDGE, que reemplazó al anterior utilísimo de Synon y Sterling, (Synposio) | Este es el recurso más disponible, más renovado, con participación amplia de desarrolladores y miembros de CA, provinientes de todo el mundo, y de la más amplia variedad de plataformas y ambientes de aplicación. |
| Las FAQs y Quiz de Nicola Zordan | Nicola mantuvo una copia de la recopilación escrita por Mark Hill, lo que permite ver la que ahora no está disponible en su sitio indicado en las FAQs de la ayuda de Plex |
| Los escritos de Lucio Gayosso | Lucio mantiene un creciente repositorio de documentos sobre temas específicos, tales como Websydian y Cristal Report |
| Los Recursos ofrecidos por Desynit | Desinyt puso a disposición de la comunidad de desarrrolladores un buen número de tips, especialmente basados en variantes Java y C++ |
| Los recursos ofrecidos por Omelette Software | Omelette Software ofrece un pequeño pero útil conjunto de recursos basados en c++. Algunos de los productos ofrecidos por la compañia son también de libre disponibilidad. |
| Las FAQs de Websydian | En el sitio de Websydian, existe abundante ayuda y documentación en línea para rever en caso de problemas |
| Los sitios personales de varios desarrolladores y consultores | Ya mencionados aparte, es conveniente recurrir a ellos siempre |
Problemas vinculados con el manejo del modelo
- Mi modelo grupal se corrompio y necesito recuperarlo
- Si usted está en una versión anterior a la 5.1: o
tiene un backup, o tiene paciencia para reconstruír un modelo
grupal reescribiendolo a mano desde un modelo local.
En realidad, el punto básico en la pérdida del modelo es el punto anterior: la política para no perderlo. Puede ver en la discusión de la administración de cambios, más sobre este aspecto.
Si tiene 5.1 (en adelante...), usted puede recurrir a la exportación del modelo local, usando la opción correspondiente en el menú Archivo de Plex. Si bien debe seguir la ayuda en detalle, tenga en cuenta la principal observación: la exportación le dará un corte, una fotografía del modelo, en una configuración dada. Deberá planificar cuidadosamente este aspecto, ya que podrá tener una visión "plana" del modelo, pero igualmente esto es mucho mejor, infinitamente mejor, que la primera solución indicada.
Sin embargo, también el uso de la exportación como XML puede llegar a ser muy trabajoso, y debe ser planificado. Nunca intenté recuperar un modelo de una sola vez, y sospecho que no debería intentarlo si no dispongo de menos de un GB de memoria RAM para trabajar. Partiendo de que la pérdida de un modelo grupal es el mayor desastre que puede afrontar con Plex, debe planificar cuidadosamente el trabajo: recomendaría trabajar en varias máquinas simultáneamente, en lo posible todas ellas con el máximo de memoria RAM que pueda comprar o arrendar para la ocasión, y un plan de tiempo de varios días cuando menos. Para poder avanzar, parta de las unidades de trabajo más pequeñas posibles, reconstruyendo el modelo desde los átomos hacia los planetas. Tome un grupo de campos integrantes de una tabla, y llévelos, Luego lleve la tabla, luego las vistas, y así subiendo en la complejidad. Trate de evitar el "traverse entities", ya que igualmente las irá reconstruyendo desde lo pequeño. Limítese a las "large properties" imprescindibles en cada paso. Tenga en cuenta que tampoco importa si sobreescribe algo que acaba de levantar, porque igualmente lo está integrando al mismo modelo. - Localizando Constantes Duplicadas después de una combinación de modelos
- Como parte de la tarea de actualizar un modelo grupal, pueden
existir conflictos por duplicidad de cambios en dos o más
modelos locales. Usualmente, se produce porque dos modelos crean
cambios a un mismo objeto; por ejemplo, un campo con valores
modificados en dos modelos. En general, el caso se resuelve al
actualizar el modelo grupal, ya que la actualización es
secuencial, y el segundo recibe el aviso de la primera entrada. Pero
existe una excepción, y aún en un caso "simple", un
usuario no experimentado podría hacer que el conflicto
permanezca. La excepción mencionada es el uso de la
función de importación, ya que al
importar, si bien el conflicto también es advertido, no es
fácil de analizar dónde está el problema. Si en
lugar de mantener el valor propio o sobreescribirlo, se opta por
mezclarlo, el resultado serán dos valores iguales en el mismo
modelo. Se pueden ver, por lo que es un mal menor, ya que de todas
formas son objetos distintos, pero, en el caso de valores, llevan a
confusión. Por lo tanto, es el momento de eliminar a uno.
Pero...Cuál se debe eliminar? El que no haya sido usado todavía en ningún lugar. Si eliminara el otro, el resultado será que quedarán referencias perdidas en algún diagrama de acción. Para eso, debo saber cuál es cada uno. Aquí interviene el identificador interno de cada objeto: Cada objeto dentro de un modelo tiene un identificador interno único en todo el repositorio; lo que quiere decir que se puede renombrar un objeto, pero no perderá su surrogate, identificado con un número y un nombre. Asociado a éste hay un conjunto complejo de información, entre las cuales está la fecha de su último cambio. Entonces, existen dos vías de búsqueda del objeto invocado en diagramas y otros casos: uno, ver exportando a xml la función que se analiza. Al hacer esto, el surrogate es mostrado asociado con el objeto, en el caso en que se use. Otro, enfocando el objeto en análisis (por ejemplo, dos constantes iguales), y analizando su información (con botón derecho, Objeto, Información, y analizar número de objeto, y última actualización). Abajo vemos la información de una constante, con indicación de los datos señalados. Conociendo ésto, eliminamos el más nuevo de ambos, o el no usado. Figura 1: Seleccionando un
valor
Figura 1: Seleccionando un
valor  Figura 2: Visión de los
identificadores del modelo con XML (Export)
Figura 2: Visión de los
identificadores del modelo con XML (Export) - Descartar frecuentemente el modelo local
- En realidad, las reglas son dos: Actualizar frecuentemente el modelo grupal, y descartar luego el modelo local. Cada modelo local guarda información propia, y puede llegar a diferir con la información que el modelo grupal contiene. La vía segura y simple de mantener la información del repositorio común, es descartarlo cada vez que terminó de actualizar. Es importante no perder de vista el mantener las opciones definidas para generación, si fuera necesario: El archivo .bld asociado al modelo será creado vacío (con las opciones default) cuando creemos un nuevo local. Existen dos formas de conservar las definiciones previas: 1, cortar y pegar desde el bld anterior, todas las definiciones. 2, llamar al modelo local nuevo igual que el anterior, y salvarlo en el mismo directorio. De esta forma, el .bld se llama igual que el anterior, y se omite su creación al existir uno. No obstante, una práctica necesaria es hacer backup del .bld cada vez que se hace una copia de seguridad del modelo local. En una politica de administración de cambios, el .bld debe ser incluído.
- Cómo crear los objetos en un ambiente colaborativo
- Cuando múltiples desarrolladores generan y compilan en un
mismo modelo, debe prevenirse el riesgo de que se produzcan conflictos
de nombres, o de funcionalidad. Estos pueden ser: creacion y
compilación de un mismo objeto con distintos nombres, o
sobreescritura de un objeto compilando simultáneamente dos o
más veces un mismo objeto. Este segundo caso es un típico
problema de administración de cambios, que primariamente se
resuelve teniendo una política para manejarlos (sea que se
compile en un área separada de cada desarrollador, o que
sólo uno trabaje en un área de problemas, pero siempre,
que exista alguien que alguien autorice el ingreso de objetos a un
repositorio único). Pero de todas formas, aquí existe un
riesgo oculto que se vincula con el primer tipo de riesgo: al generarse
un objeto, puede arrastrarse la generación y compilación
de funciones internas dependientes, no directamente enfocadas, pero que
pueden estar en distinto grado de desarrollo en dos ambientes. Es
decir, un objeto modificado por dos usuarios puede estar en distinto
grado de desarrollo, y provocar resultados inesperados al enviarse a
compilación en un ambiente único (por ejemplo, una
función llamada que pasa distinto número de
parámetros en dos versiones en desarrollo; una función
sin nombre definitivo que asume dos nombres distintos; una tabla a la
que se le modifica un campo en tipo o longitud, o herencia.).
En todos los casos, la solución primaria, aparte de definir un sistema de autorizaciones para enviar al repositorio, es 1, asignar nombres a cada objeto, 2, actualizar el modelo grupal por parte de todos los intervinientes, y 3, resolver los conflictos que pudieran aparecer, y redistribuir la nueva versión del modelo.
Problemas simples vinculados con el manejo de la configuración
- Mi panel aparece sin el diseño que le había dado
- Asegúrese de haber establecido la configuración que corresponda a su variante; los paneles son dependientes de la variante. Si se usó herencia de un objeto de librería, asegúrese de que esté configurada la librería correctamente (Extensible a la variante y nivel)
- El mensaje que debía ver no aparece, y la aplicación continúa adelante cuando debía verlo!
- El mensaje fue creado, pero la constante que se desea representar no fue escrita, o lo fue en otra variante, y no es visible en su configuración actual. Preferentemente, mueva el texto a la configuración base
- Compilé una función y ahora aparecen llamadas a una función que no estaba prevista, con un nombre extraño (szab...)
- La función llamada no posee nombre de implementación, o el nombre no fue creado en la variante en que se encuentra trabajando, y Plex le está asignando un nombre automáticamente. Si la función correspondiera a un objeto de librería (se trata de un objeto que no es modificable en el modelo en que está trabajando, ya que no tiene autoridad sobre la librería), en ese caso, se generará una llamada al surrogate name. Para saber cuál es la función llamada, deberá buscar el surrogate name directamente en el source code.
- Truncamiento en constantes
- Un valor en el modelo es representado físicamente por una constante que se ingresa manualmente como Large Property. Si al escribir la constante no se tiene en cuenta el tamaño del campo tal como se definiera, la constante será truncada al momento de generarse la función. Más frecuentemente, el problema puede aparecer cuando se altere la longitud del campo, o uno del cual herede, si la longitud fue definida en ese nivel de la herencia. El resultado será que ninguna comparación funcionará, y nos daremos cuenta luego de varios intentos, o luego de misteriosos disfuncionamientos.
- Truncamiento en nombres de implementación
- Los nombres de implementación dados a funciones o tablas y vistas, son variante dependientes, y esto tiene una explicación justamente en éste problema: las reglas de nombramiento de tablas, etc, pueden variar de una plataforma a otra, y un nombre puede no funcionar en otra variante. El resultado será que el generador dará un aviso de truncamiento al escribir el código, y que el resultado será una función o tabla que se llama de otro modo del esperado. Hasta aquí el problema podría ser menor, porque en todo caso, siempre será llamado por ese nombre válido en la variante, siempre que no tenga llamadas incrustadas de alguna forma que refieran a la constante por otro medio (un procedimiento externo, por ejemplo). El problema más grande se presenta si acaso existe un estándar de nombres, que al aplicarse resulta en el truncamiento a nivel de un punto en el que dos o más objetos todavía no se diferencian (pej: nombrefun01 y nombrefun02, resultaran en nombrefu si usamos RPG. A cuál nos referimos?). En esta situación, el último objeto compilado/generado, será el existente. Luego, encontraremos que tenemos extraños mensajes de error (diferencia en el número de parámetros, pej.), cuando la aplicación se ejecuta. Por esta razón, dos reglas se deben observar: 1- conocer las reglas de formación de nombres para la variante para la cual se está generando, y crear nombres de implementación válidos, en la variante. 2- Revisar los mensajes del generador (!)
- Implement ...NO
- Un proceso misteriosamente no hace lo esperado, o no hace nada. Luego de depurar y seguir la secuencia de actividades, descubrimos que una función no se ejecuta, simplemente. Luego de dar vueltas a la lógica, caemos en la cuenta de que ni siquiera fue generada. Y luego de darle miradas al revés y al derecho, nos damos cuenta que, o tiene un triple que dice Implement ...NO (!), o lo tiene en la herencia de un ancestro. Este es el caso común de la función Process some instance en las Clases, que está construída así, y debe agregarse el triple de implementación al usarse
- Type ...Internal
- Una función no compila en RPG si su tipo es Internal. En este caso, el compilador advierte con un mensaje. Usualmente no es un problema, ya que será incluída en la función que la llama. El problema se puede presentar especialmente si se trata de una llamada desde un programa cliente, ya que el compilador no la procesará. Si su programa es C++, el inconveniente resultante es de modificación de la arquitectura, si no fue decidido deliberadamente, ya que la función se incluirá en la DLL que lo llama, pudiendo así resultar en programas ejecutables inesperadamente grandes. Además, se generará como parte de cada dll que lo llame
- C Format...
- La definición del tipo de datos puede requerir mayores precisiones que las que el generador determine en base a las definiciones generales del modelo. En el caso de funciones clientes C, esto debe tenerse en cuenta. Por ejemplo, un campo numérico de longitud grande, digamos 17 dígitos, va a generarse como un tipo Long, y pudiera producir errores de redondeo. El campo conservado en una tabla AS400 con 17 dígitos puede indicar un número, pero al ser mostrado en una grilla, dar un desvío en su menor dígito. Si se pretendiera visualizarlo (siendo clave) con un Single Fetch, la fila no sería encontrada. En este caso, se debe cambiar el tipo a C Format...Fixed Decimal, aún cuando se trate de números enteros.
Tips en el modelado
- El uso de Surrogate
- Este patrón es una versión mejorada de la entidad
numeradora de las clases de negocios de OBase. En su versión
actual, existen algunas interesantes variantes para su uso.
¿Qué es una entidad Surrogate? Es una entidad identificada por un número secuencial automáticamente asignado, con la finalidad de identificar unívocamente a una fila. Adecuada para entidades transaccionales, de auditoría o log, o para la identificación secuencial de documentos. Una discusión detallada del uso de estas claves se puede encontrar en Datamodel.Org.
La versión actual, en los patrones de Foundations, se compone de dos partes: uno, el patrón de Surrogate en sí, y otro, Surrogate System, completa el mecanismo de soporte de asignación de claves o identificadores. El primero define una clave numérica con un mecanismo de actualización automática (getnextnumerator), en la llamada a Insert Row, y el segundo, es el repositorio que almacena los números, con dos campos: un identificador de la tabla originadora del numerador, y otro el numerador incremental.
Cómo se implementa:
Se hereda de Surrogate: Mi_entidad is a Surrogate.
Se reemplaza Surrogate System por la entidad (que se debe crear heredando de Surrogate System) que se va a usar para repositorio: Mi_entidad replaces Surrogate System ...By... Mi_SurrogateSystem.
Y se reemplaza el campo Surrogate por el campo (que hereda de éste) que se desee usar: Mi_surrogate replace Fld Surrogate ...by... MyFldSurrogate.
Cuando se inserta una fila, insertrow llama a una función que consulta el siguiente número secuencial en Surrogate System, y lo incrementa. El insert devuelve como output el numero asignado, para cualquier uso posterior (mostrarlo, usarlo como clave hija en otra entidad, etc).
Esto es lo básico. Qué variantes interesantes se pueden derivar de este modelo:
1. Surrogate Owned, donde la clave numérica es hija de una clave de una entidad padre.
2. Numerador como clave de orden menor, con otras claves antepuestas en orden. Para que el numerador esté en otro orden que primero, simplemente se debe declarar la clave numeradora en forma explícita, en el orden que se desee. Eso es suficiente.
3. Numeradores para cualquier campo, aunque no sea una clave. Esto se logra así: Usualmente, en insert row, en la Inicializacion, dentro de Sub Set table name, en Pre Point Override table name, se pasa el nombre del campo que se desea numerar como clave (si se desea cambiar el nombre de la tabla asignada) Éste es pasado a la función getnextnumerator. Esto mantiene un secuenciador para ese nombre. Si se desea usar un numerador para cualquier campo, lo que se debe hacer es agregar una llamada a getnextnumerator, pasando el nombre del campo que se desee en el insert de la entidad que se va a procesar, y luego, entregando el resultado de la llamada a esta función al insert. cambiar el campo Localcon el nombre de implementacion del campo
Tips en el ciclo de construcción
- Actualización de valores
- Un campo puede declarar un conjunto de valores al momento de
definirlo, pero luego frecuentemente esos valores pueden ser ampliados,
creándose otros nuevos. Es sabido que los nuevos valores no
se agregan automáticamente a paneles y reportes, por lo que
deben ser arrastrados manualmente desde el Object Browser hasta
el campo en el panel (si no lo sabía, téngalo presente).
Sin embargo, a veces se ve esto limitado a los campos visibles en el
panel, pero vale también para cualquier otro no visible. El
problema aparece cuando se valida con una metaoperación un campo
con un conjunto de valores que ha variado desde la construcción
inicial del panel. Si la metaoperación llama a la función
validadora usualmente asociada al campo status, la función
controlará el set actual de valores, pero los encontrará
cambiados en el panel. Esto produce la falla de la validación
sin motivo aparente, ya que el campo no está visible, y nunca se
ingresó un valor.
Entonces, cuando un dato definido con herencia de status, que tiene una función validadora, emite mensajes inesperados en un panel que herede de Insert o Update, implica casi absolutamente seguro, que tiene nuevos valores que no fueron incluídos en el panel. Solución, tome el valor del Object Browser, y arrástrelo al campo en el panel, y regenere el panel.
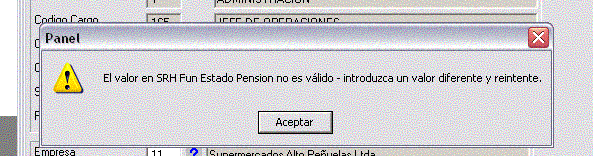 Figura 1: Mensaje por una validación "oculta"
Figura 1: Mensaje por una validación "oculta" 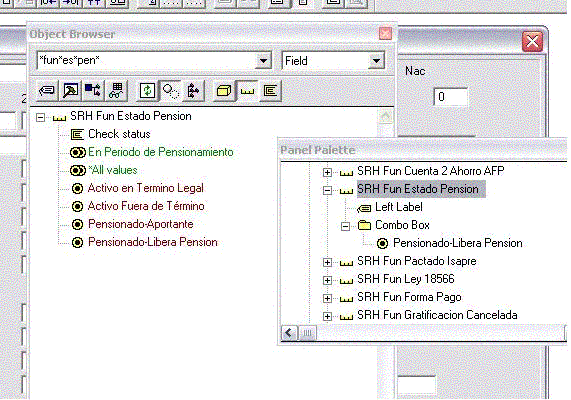
Figura 2: "Estado Pension" en panel debe agregar tres valores
Implementando en ISeries
- Modificando instrucciones del compilador
- Símplemente, tengalo en cuenta. El tema está explicado en la ayuda de Plex. Usted puede modificar las opciones que el compilador ejecuta cuando somete una compilación, ya que los comandos y parámetros ejecutados son almacenados externamente en el archivo de mensajes YKTRCMSG. El tema está discutido en la Guia de la variante AS400 5250.(AS400 5250 Platform Guide, Making Compiler Overrides for AS/400 Builds)
- Cuidado con los nombres
- Como se indica en la sección anterior, en RPG los nombres de implementación de campos y funciones siguen reglas estrictas de longitud. Si no las tiene en cuenta, los resultados son impredecibles, ya que el generador truncará los nombres a la longitud básica, creando posibles duplicados. Hay una cuestión adicional: las reglas del RPG son más limitativas que las del ISeries, con lo que debe ignorar éstas. Así, un archivo puede tener hasta diez caracteres de longitud en ISeries, pero sólo ocho en RPG. Esto vale para la variante soportada por Plex. Una vez que la versión 5.5 esté disponible, estas consideraciones deberán ser revisadas, dada la extensión a RPG ILE.
- Funciones de manejo de strings
- En general, las funciones de manejo de cadenas de caracteres es
relativamente limitada en Plex, lo que se acentúa para la
plataforma ISeries. Sin embargo es simple crear source code que recurra
a las funciones existentes en RPG (CAT, CHECK, CHECKR,
SCAN, SUBST, XLATE). Un límite que
existe es que un formato de campo carácter variable, que
sería lo más conveniente para manipular cadenas de
caracteres, no es soportado por el RPG/400, que considera
"variable", una longitud de 256 caracteres máximo. Pero es
posible rodear el problema llamando a una función externa RPG
ILE, que sí soporta el concepto de campo carácter
variable (Gracias a mi colega Sergio Guamán, que
desarrolló el primer caso aquí en Rendic).
En la sección dedicada a Source Code habrá proximamente algunos ejemplos. - Compilar los mensajes
- Los mensajes son conservados y referidos desde un archivo de mensajes. Si envía mensajes a tareas en el servidor ISeries (Format message usualmente, para generar datos con un formato predeterminado), recuerde que los mensajes deben compilarse. El resultado de no hacerlo, es que los datos aparecerán en blanco. El archivo de mensajes se define en las opciones de configuración de generación y compilación (definiciones del servidor ISeries), y la opción de compilación se encuentra en el menú de build. Normalmente, la generación dá mensajes de error para mensajes no orientados al servidor, pero esto no produce consecuencias.
Cuestiones de estrategia
- Cómo manejo un sistema complejo, donde muchas áreas interactúan?
- Esta es una cuestión más que genérica,
seguramente muy clara para la mayoría, pero quizá
útil para los grupos principiantes. Es conveniente trabajar en
módulos, separando las áreas de dominio de su problema.
Aplique OOD, o lo que usted prefiera, pero trate de armar areas bien
definidas que interactúen, pero que puedan mantenerse
separadamente. Luego es posible recurrir a los servicios que cada
módulo entregue, mediante su llamado como librería: basta
que se agreguen al modelo como librería, y se refresque
regularmente su contenido. Cada vez que usted haga login a su modelo,
las novedades incorporadas a la librería serán
advertidas, y las podrá incorporar sin dificultades, y con
seguridad. Asegúrese de que no genera situaciones donde quede
comprometido por una doble definición: cada objeto debe ser
definido en un solo modelo, aunque sea usado en una multitud.
Existen medios para que las referencias sean hechas incluso sin que la librería esté asociada: apuntando al nombre de implementación del objeto, y estableciendo implement...no, lo que lo convierte en una caja negra fuera del alcance del modelo host. Este método se puede ver usado en la librería OBSEC, un veterano módulo de clases de Plex que es posible incorporar para agregar control de ingreso de usuarios a un sistema. La funcionalidad de OBSEC puede implementarse de manera simple, ya que ambos módulos (el del usuario y el de seguridad) nunca se conocerán. Sólo se requiere habilitar algunas metaoperaciones en tiempo de diseño, para que el sistema sometido a control de seguridad incorpore el mecanismo del módulo externo. Estudie este caso en busca de avanzadas formas de interactuar entre módulos.
Qué ventajas tiene este esquema: mantener un modelo manejable. Un modelo sin delimitación de alcance puede llegar a un tamaño gigantesco, a medida que nuevas funciones le son requeridas, y convertirse en algo imposible de administrar: Requiere más y más memoria en la estación de trabajo, requiere tiempos imposibles para su actualización, requiere el uso continuo de submodelos para extractar sólo partes necesarias. Es más fácil de asignar el trabajo, más fácil de recuperar si un día se destruye el modelo de grupo. - Paso de Clases a Patterns?
- Por varias razones, seguramente si, hágalo, sin
temor ni arrepentimiento.
Primero, porque el compromiso de CA (como lo fue el de Sterling) es de mantener la compatibilidad, pero ya no existen nuevos desarrollos en las Clases. Segundo, porque cuando las Clases fueron diseñadas, una virtud esencial de los Patterns aún no había sido creada: la herencia múltiple, explotada a través de los puntos de edición, admitiendo un pre y post edit point. Los Patterns fueron diseñados para poder ser mezclados, combinados, permitiendo aplicar herencia de múltiples artefactos para lograr un nuevo resultado. Pruebe, si no lo hizo, crear una función de edición que combine un Update, un Grid, un Grid2, y vea el resultado. Entonces, una virtud superior de los Patterns, es su mayor granularidad, su mayor simplicidad, que permite escalar una pirámide de combinaciones. Por supuesto, puede ir a la cima de la pirámide con algunos patterns, pero puede quedarse también en sus sólidos y simples bloques de fundamento. Un caso claro es Websydian.
Existe mucha inversión efectuada en Clases, y teme dar un nuevo paso?. He visto esta situación en un buen número de casos, y puedo hablar por mi experiencia: He participado en desarrollos donde el grueso de los módulos que componen la estructura informática de la empresa estaban desarrollados sobre clases, y se fue pasando gradualmente a nuevos módulos, o nuevas funciones, basadas en patterns. Es posible incluso aplicar herencia sobre una entidad de ambos orígenes, haciéndolo con cuidado. Pero no hay ninguna necesidad de eternizarse en el conjunto de clases preexistentes. - Mantener una capa estándar corporativa
- Ha sido una práctica recomendada, incluída en general en cualquier tutorial, y sigue siendo recomendable, pero no siempre cumplida. Es conveniente desarrollar un repositorio base de objetos y patrones (o patterns) que sean aplicados en los modelos que representen luego el negocio corporativo. Es preferible definir una capa con los tipos de datos, los valores por defecto, los valores corporativos, las máscaras de edición, la apariencia estándar de paneles, mensajes, reportes, etc. Es preferible delegar a esa capa cada cambio que deba ser usado como valor genérico, porque un cambio propuesto se hará una sola vez, y luego será heredado por cada modelo que lo use. Más aún, al producirse una actualización de versión, si se diera el caso de que un objeto del repositorio de Plex que se hubiera usado en esa capa cambiara, el cambio se resolvería sólo en esa capa, y su propagación sería más simple. Por supuesto, "capa" se refiere a un modelo grupal de estándares, que sea aplicado como librería a todos los módulos del negocio. Todo esto ya está dicho en los tutorials, pero no está de más recordarlo, si desea trabajar menos.
-